

Время на прочтение
Сегодня мы рассмотрим три школы: ШАД от Яндекс, Школу анализа данных от VK и AI Masters.
Школа анализа данных ШАД, Школа анализа данных от Vk и AI Masters — это образовательные учреждения, специализирующиеся на обучении анализу данных и машинному обучению. Они имеют некоторые сходства, но также и различия, которые могут быть важны для потенциальных студентов при выборе школы.
Мы проанализируем сильные стороны каждой школы, процесс поступления, программы, сроки и сложность обучения.
- ШАД
- AI Masters
- Обзор конкурентной структуры рынка онлайн-образования России
- Поступление
- На пути к индивидуальному образованию
- Почему персонализированное образование — это сложно
- Яндекс. Репетитор
- Простейшая аналитика
- Бесконтекстные модели сложности
- Рекомендации
- Что дальше
- Извлечь смысл. Проблемы анализа данных в образовании
- Программы
- Как проходит учеба в школах?
- Выводы
ШАД
Школа Анализа Данных (ШАД) — образовательная программа, созданная Яндексом, одной из крупнейших IT‑компаний России. Ш АД имеет высокий авторитет в России и за ее пределами. Если вы хотите получить мощную программу PhD в США или работать на позиции Data Scientist в крупных IT‑компаниях, то ШАД — отличный выбор.
Школа анализа данных от VK — это программа для специалистов, уже имеющих опыт работы от 1 до 3 лет в сфере анализа данных или разработки. Она подходит для тех, кто знает языки разработки, такие как Java и Python.
AI Masters
AI Masters — это образовательная программа в области наук о данных от Института ИИ МГУ. Курсы соответствуют магистерским программам в области машинного обучения и бизнес‑аналитики от ведущих университетов мира.
Обзор конкурентной структуры рынка онлайн-образования России
Несмотря на то, и отчасти благодаря тому, что рынок онлайн-образования России еще только формируется, он уже высоко конкурентен. Помимо крупных EdTech-конгломератов (VK, Skyeng, TalentTech, Яндекс) на рынке присутствует достаточное количество крупных, по российским меркам, игроков, в том числе из ТОП-15, которые представляют реальный интерес для анализа конкурентного присутствия.
Диаграмма 13 «ТОП-15 участников рынка онлайн-образования России»

Лидер сектора бизнес-образования, компания «Like Центр», является вторым, после «Skillbox Holding Limited» (с выручкой более 10 млрд руб.), номером ТОП-15 компаний рынка онлайн-образования России, с годовой выручкой свыше 7 млрд руб. (10% доля общего рынка онлайн-образования) в 2021 году.
Среди отдельных крупных игроков рынка онлайн-обучения России в 2021 году следует также выделить: университет «Синергия» с выручкой свыше 2 млрд руб. и лидера сектора корпоративного обучения университет «Актион» с выручкой около 2 млрд руб., онлайн-школу подготовки к экзаменам «Умскул» с выручкой свыше 2 млрд руб., онлайн-платформу корпоративного обучения «iSpring» c выручкой около 2 млрд руб., платформу для онлайн-школ «GetCourse» с выручкой 1,7 млрд руб., образовательный центр «Maximum Education» с выручкой 1,6 млрд руб. и детскую онлайн-школу по изучению английского языка «NovaKid» с выручкой 1,5 млрд руб.
Общий анализ деятельности ТОП-15 лидеров рынка 2021 года дает представление о конкурентном присутствии и о наиболее высоко конкурентных нишах рынка онлайн-образования России, среди которых сектор дополнительного профессионального образования, являющийся на текущий момент времени уже прямым конкурентом сектора высшего образования (четыре компании с совокупной 25% долей общего рынка), сектор изучения иностранных языков (две крупных компании с совокупной 16% долей общего рынка), сектор среднего школьного образования (четыре крупных компании с 11% долей общего рынка), сектор бизнес-образования (одна доминирующая компания с 10% долей общего рынка), сектор корпоративного обучения (две крупных компании с совокупной 5% долей общего рынка).
Общая выручка компаний ТОП-15 рынка онлайн-образования России составила в 2021 году порядка 51 млрд руб. (70% доля общего рынка).
Несмотря на достаточно высокую конкуренцию, занятую крупными мультиструктурными компаниями 44% долю текущего рынка онлайн-образования России (ТОП-100 EdTech-компаний), потенциал развития российского рынка, в том числе в силу его молодости, не исчерпан. Среди характерных особенностей зрелого, сконцентрированного, сформированного рынка, наличие хотя бы одной компании «единорога», оценка которой равна или превышает 1 млрд долл., а также наличие компаний второго слоя выручки, которые пока отсутствуют.
Именно компании второго эшелона, которые, возможно, только собираются выходить на рынок в ближайшей перспективе, наиболее технологичные из этих компаний, продолжат формирование рынка онлайн-образования России в среднесрочной перспективе и именно они, в первую очередь, будут представлять интерес для инвесторов, с точки зрения автора, в дальнейшем.
Существуют все предпосылки того, что будущий лидер, «единорог» рынка онлайн-образования России, пока еще неизвестен широкой аудитории или еще даже не создан.
В информатике, наряду с понятием «информация», часто употребляется понятие «данные». Данные – это результаты наблюдений над объектами и явлениями, которые по каким-то причинам не используются, а только хранятся. Как только данные начинают использовать в каких-либо практических целях, они превращаются в информацию.
Несмотря на то, что выводы любого аналитического исследования отчасти субъективны, из любой информации можно извлечь пользу, чего я Вам и желаю.

1. Исследование российского рынка онлайн-образования и образовательных технологий: Edumarket, 2017-2021
2. Исследование Российского рынка онлайн-образования: Edmarket, 2020
3. Российский рынок онлайн-образования: Liberty Marketing, 2020
4. Мониторинг экономики образования, НИУ ВШЭ, 2016
5. Р БК Тренды, по данным Smart Ranking: 2019-2022
6. Исследование российского рынка онлайн-образования, «Нетология», 2022
7. Иные открытые источники информации.
Поступление
ШАД Яндекса всегда славился своим жестким отбором. Претендентам необходимо пройти три этапа: онлайн‑тестирование, онлайн‑экзамен и личное интервью.
Первый этап представляет собой тест с математическими и программными задачами. На втором этапе претендентам предстоит решить задачи по математике, алгоритмам, программированию и основам анализа данных. Наконец, на третьем этапе состоится личное интервью по трем направлениям: алгоритмы, программирование и мотивация.
Отбор в Школу анализа данных от VK начинается с онлайн тестирования по основам математического анализа, программированию и машинному обучению. Некоторые кандидаты могут быть приглашены на собеседование с преподавателями, где им предстоит выполнить задания на чтение и написание кода, а также решить кейс. На собеседовании студентам необходимо будет прокомментировать свои решения и ответить на вопросы эксперта.
Отбор в AI Masters начинается с прохождения онлайн‑тестов по стандартным математическим дисциплинам. Затем необходимо пройти контест по BI и DS или сдать онлайн‑экзамен.
На пути к индивидуальному образованию

Наверняка почти каждый мечтает о персонализированном образовании: двигаться к своей образовательной цели максимально коротким путём, решать только те задачи, состав и сложность которых подстраиваются под тебя, с пользой проводить любой отрезок времени независимо от длительности и структуры. Неважно, будь то пятиминутный перерыв от работы или ежевечерние занятия на протяжении месяцев.
Такой инструмент позволил бы экономить огромное количество времени и при этом добиваться значительно лучших результатов. Эффективность обмена знаниями значительно повысилась бы, а вслед за этим ускорился бы и прогресс.
Но пока человечество совершает лишь робкие попытки подобраться к пониманию, как создавать такой инструмент. Свою попытку осуществила и команда Яндекс. Репетитора. Сервис, запущенный менее двух лет назад, накопил данные о ста миллионах решений различных задач, и этого достаточно для интересной аналитики. Понятно, что образование состоит не только из задач, но сегодня мы сфокусируемся на них.
В статье я расскажу, какую аналитику мы научились строить на базе собранных данных и благодаря каким свойствам сервиса она оказывается возможной. В самом конце вас ждёт небольшой отчёт о нашей первой попытке построить сервис для персонализированного образования и о результатах этого эксперимента.
Почему персонализированное образование — это сложно
Построение современной персонализованной образовательной системы — сложная задача. С точки зрения специалиста по анализу данных ситуация выглядит так:
Яндекс. Репетитор
Список выше можно продолжать, но перечисленные в нём проблемы поддаются решению. На мой взгляд, хороший план может выглядеть так:
Исходя из таких рассуждений и появился сервис Яндекс. Репетитор. Это, в общем-то, большой задачник для школьников, готовящихся к ЕГЭ или ОГЭ. Школьные задачи можно решать по отдельности или в составе вариантов. Конечно, можно и просто смотреть разборы или оставлять задачи без ответов. При анализе такие случаи потребуется отбрасывать.
Мы сделали блок рекомендованных задач. Предположим, школьник попадает на страницу предмета и для него собрана статистика — достаточный объём решений заданий этого предмета. Каждый такой школьник может увидеть следующий блок:
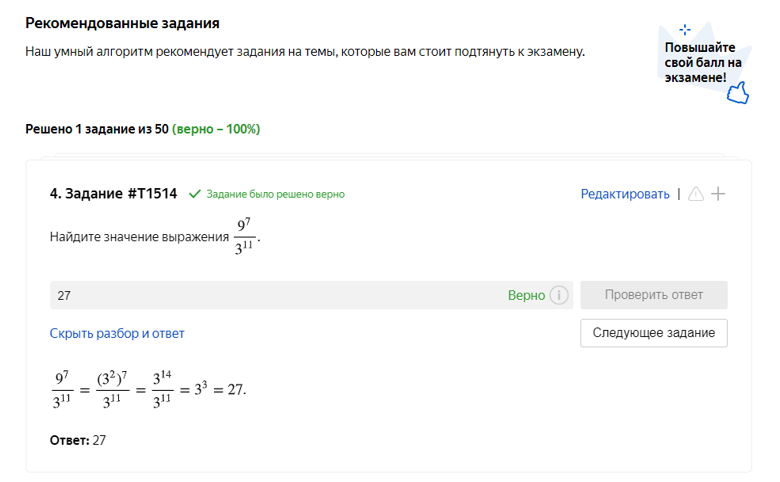
Ссылка на этот блок
В нём демонстрируются задания, подбираемые разными вариантами алгоритмов.
Простейшая аналитика
Первая группа наблюдений лежит на поверхности: можно изучать пользовательский интерес к образованию в зависимости от дня недели, времени года, времени суток и т. д.
Вряд ли кто-нибудь удивится, что максимально активные образовательные дни — это дни с понедельника по четверг. Пятница и воскресенье примерно равны, а по субботам наблюдается значительное снижение активности. На сглаженном годовом графике видно, что школьники не проявляют интереса летом, в Новый год и во время других праздников, на каникулах.
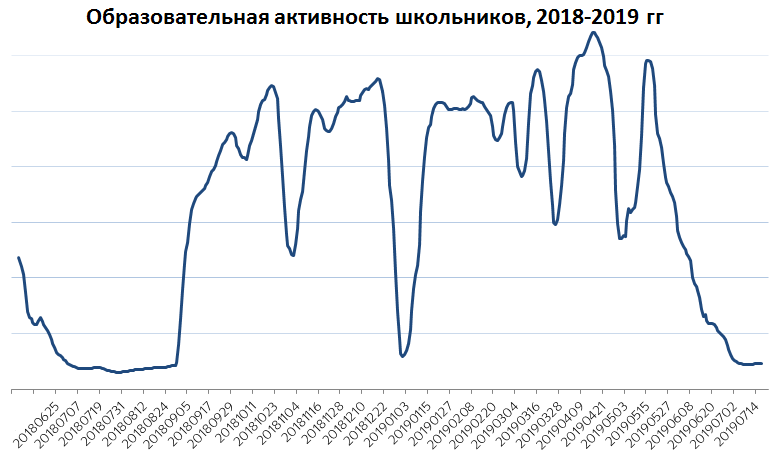
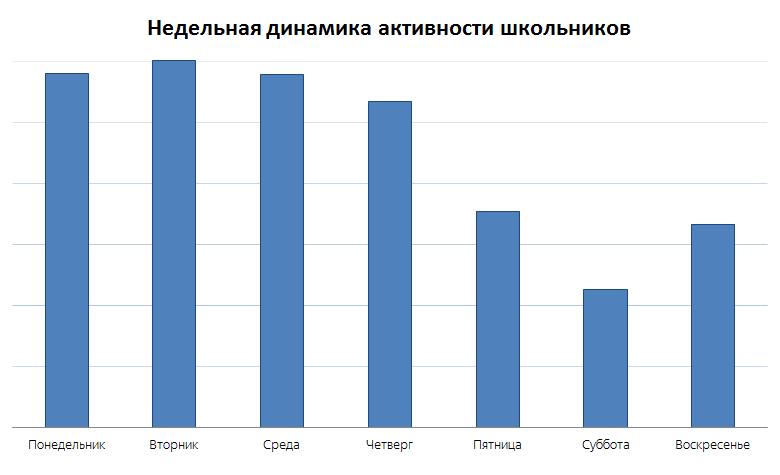
Но это всё лежит на поверхности и даже не требует создания нового сервиса — хватило бы и анализа данных веб-поиска.
Бесконтекстные модели сложности
В простейшем случае показателем сложности задачи может служить средняя успешность её решений: задача, где верными оказались 40% ответов, почти наверняка сложнее задачи, где тот же показатель составляет 60%.
Но такой анализ слишком прост и не учитывает разного уровня подготовки пользователей. Простой пример: задачи тестовой части ЕГЭ по математике профильного уровня решаются в среднем существенно успешнее задач базового уровня. Конечно, из этого нельзя делать вывод, что задачи профильного уровня легче. Просто их решают более подготовленные школьники, для которых сложность не в задачах тестовой части.
Поэтому потребуется более комплексная модель. Первой рассмотрим рейтинговую модель, которую уже давно придумали в шахматах, адаптировали к олимпиадному программированию, баскетболу и многим другим областям.
трактуется так, что пользователь
и дал верный ответ, если
и неверный, если
Сопоставим каждому пользователю и каждой задаче рейтинг — некоторое вещественное число. Точнее, определим функцию
Выбирать значения рейтингов будем простым методом максимального правдоподобия:
Выглядит немного громозко, но в действительности всё просто: такие рейтинги легко строить при помощи стохастического градиентного спуска, совсем как при обучении логистической регрессии.
Конечно, можно строить отдельные рейтинги для пользователей в рамках различных тематик. Скажем, школьник может очень хорошо справляться со стереометрическими задачами и при этом плохо с задачами по теории вероятностей. Описанный метод вполне подходит и для этого.
Приведу пример результата вычисления рейтингов для отдельных номеров задач ЕГЭ по математике базового уровня и пользователей Яндекс. Репетитора. Чтобы он был насколько-то обозрим, я оставил только четыре группы задач: две самых сложных и две самых простых.
Я привожу три характеристики для каждой темы:
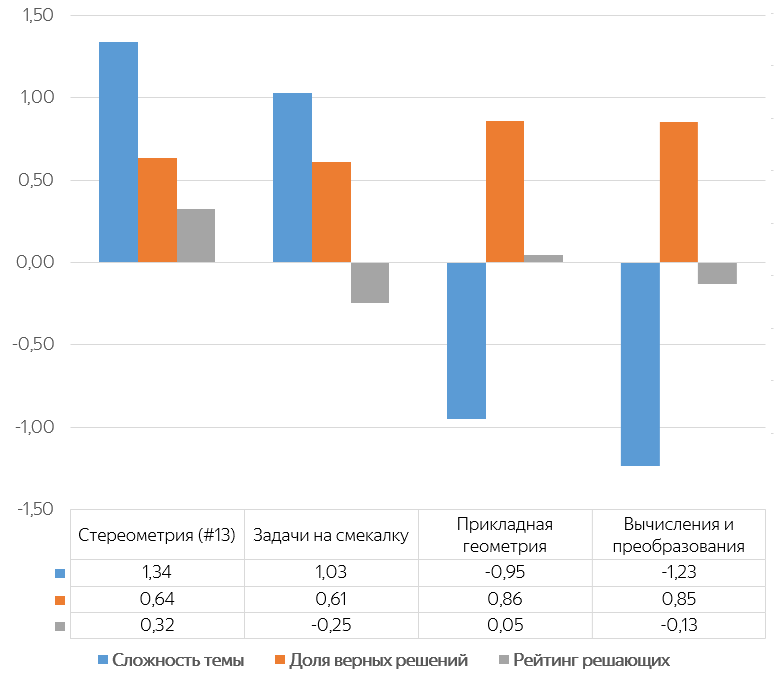
Например, в среднем стереометрические задачи решают верно чаще, чем задачи на смекалку (64% и 61% верных ответов соответственно), но именно стереометрия оказывается наиболее сложной темой. Причём задания в ней решают более сильные школьники: средний рейтинг пользователей, решающих задачи по стереометрии, оказался равен 0,32, тогда как задачи на смекалку решают пользователи со средним рейтингом -0,25. Таким образом, анализ сложности заданий требует анализа способностей пользователей, и это очень ценный вывод.
Понять, насколько рейтинги информативнее простой доли верных решений, позволяет следующее сравнение. Построим графики обеих величин, отсортировав темы по убыванию рейтинга:
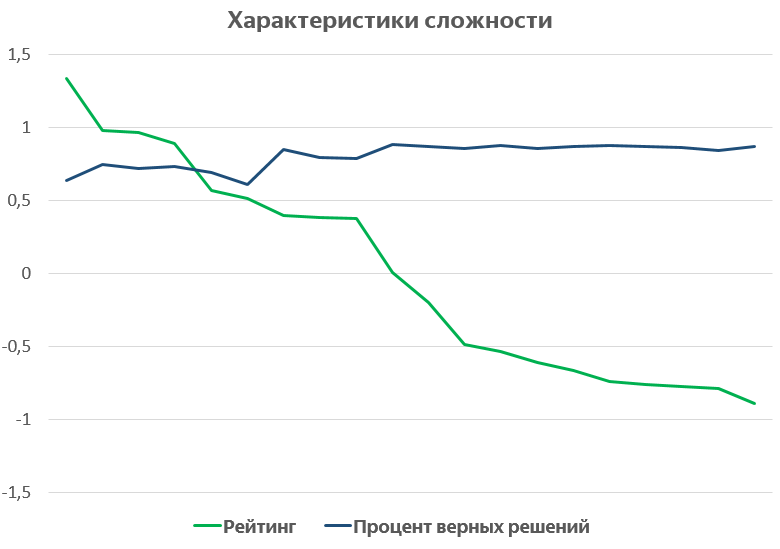
Хорошо видно, что с точки зрения доли верных ответов есть две группы задач: более сложные (70-75% верных решений) и более простые (85-90% верных решений). Рейтинги в этом смысле выглядят обеспечивающими больший разброс и большее разнообразие значений.
Последнее, на что очень интересно взглянуть: распределение рейтингов пользователей. Я построил вариационный ряд рейтингов пользователей и увидел такую картину:
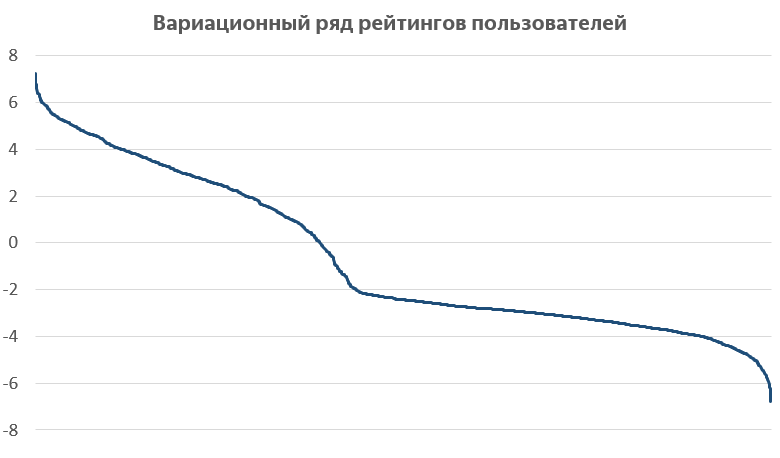
Этот график построен следующим образом. Для всех пользователей, решивших хотя бы десять задач на сервисе, построены рейтинги. Затем пользователи упорядочены по величине рейтинга, и по горизонтальной оси отложен номер пользователя в полученном рейтинге, а по вертикальной — величина самого рейтинга. Думаю, эта зависимость могла бы стать основой отдельного содержательного исследования.
В предыдущем пункте я описывал, что происходит при определении рейтингов отдельных групп задач и пользователей. Естественное развитие этой идеи — использовать модели, зависящие от свойств задач и пользователей, а не бесконтекстные рейтинги.
Например, можно в качестве признаков использовать «слова» в условии задачи. К «словам» относятся не только сами слова, но и различные специальные термы, такие как математические символы и части формул.
Обучение будет производиться тем же методом максимизации правдоподобия, а модель для простоты используем линейную. То есть фактически будет обучена модель, которая умеет оценивать априорную сложность задачи по её тексту.
Если чуть формальнее, в терминах пункта 4 необходимо переопределить функцию рейтинга для задачи:
— вес терма
. Эти веса будут оптимизироавться в процессе обучения.
Затем рейтинг задачи будет уже линейной функцией по термам, входящим в формулировку задачи. Модель сложности задач будет свободна от смещений, вызванных разными характеристиками пользователей: оптимизация весов этой модели производится одновременно с оптимизацией рейтингов пользователей.
Анализируя веса различных термов, можно понимать, какие части заданий вызывают у школьников сложности. Например, при обучении подобной модели для базовой математики получилась следующая картина:

То есть при прочих равных школьники прекрасно решают задачи с корнями и треугольниками, но вероятность успеха уменьшается, если задача требует знания логарифмов или пирамид.
Ещё интереснее добавлять в такие модели персональные свойства пользователей. Скажем, пользователи, склонные пропускать задачи (оставлять поле ответа пустым), в среднем добиваются результатов аж на треть реже других. Склонность решать варианты, напротив, является показателем качества: в среднем такие пользователи справляются с задачами на 37% успешнее.
Конечно, это не означает, что прорешивание вариантов — отличный способ подготовки (впрочем, здорово, что более упорные школьники чаще добиваются успеха). Текущий уровень анализа не позволяет определять, какие из зависимостей отражают объективные причинно-следственные связи. Есть и хорошие новости: ясно, что нужно поменять в сервисе, чтобы это стало возможным.
Рекомендации
Я хочу, чтобы развитие идей из пунктов 4 и 5 привело к созданию модели, которая бы хорошо предсказывала полезность действий на сервисе (в том числе — полезность решения тех или иных задач).
В первом приближении такую модель можно вывести из любой модели сложности задач, использовав побольше персональных факторов пользователей. Тогда можно будет вычислить ожидаемую успешность в решении задач экзамена до и после решения той или иной задачи (с учётом вероятности её успешного решения). Этот метод выглядит реализуемым, необходимо лишь собрать побольше данных и аккуратно учесть каждый bias в них. Кроме того, для демонстрации работоспособности модели потребуется эксперимент, поставленный корректно, с соблюдением всех требований double blind studies.
Сейчас я не могу похвастаться всем этим, зато могу поделиться первыми результатами, дающими надежду на итоговый успех.
Для начала посмотрим на график априорной сложности самостоятельно решаемых задач. По горизонтали — номер задачи, которую решает пользователь (например, это 100-я задача, которую он решает на сервисе), по вертикали — сложность в простейшем её понимании: какая доля всех решений этой задачи является успешной.
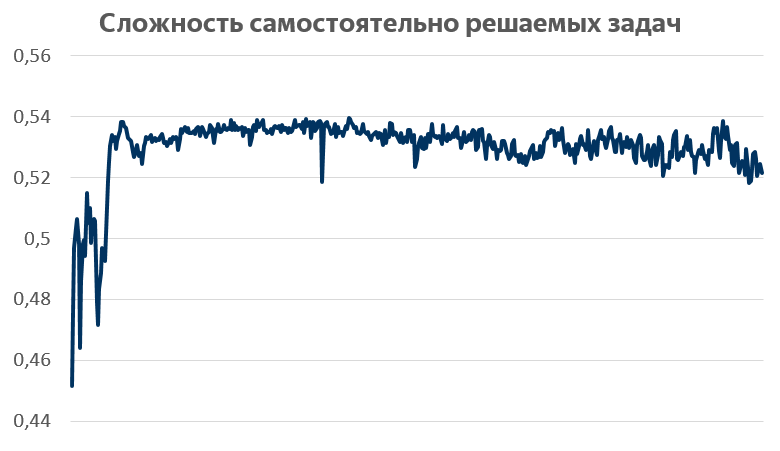
Здесь видны две важные проблемы самостоятельной подготовки. Первая: школьники решают задачи одной и той же сложности. Вторая: они решают слишком сложные задачи, с априорной вероятностью успеха всего 50%.
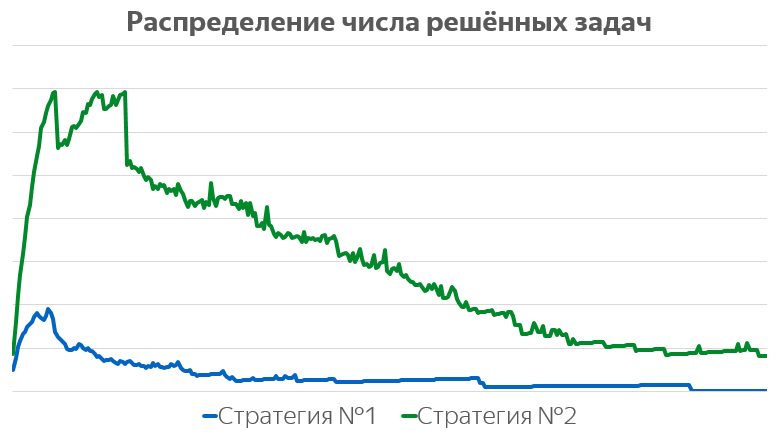
Мы на сервисе реализовали две стратегии рекомендации задач пользователям. Первая выдаёт случайные задачи, другая генерирует их неким относительно умным образом. На картинке ниже — динамика сложности предлагаемых задач в зависимости от номера.
Синяя линия показывает предсказание априорной вероятности решить задачу, зелёная — предсказание персональной вероятности решения (априорная не зависит от пользователя, персональная — зависит).
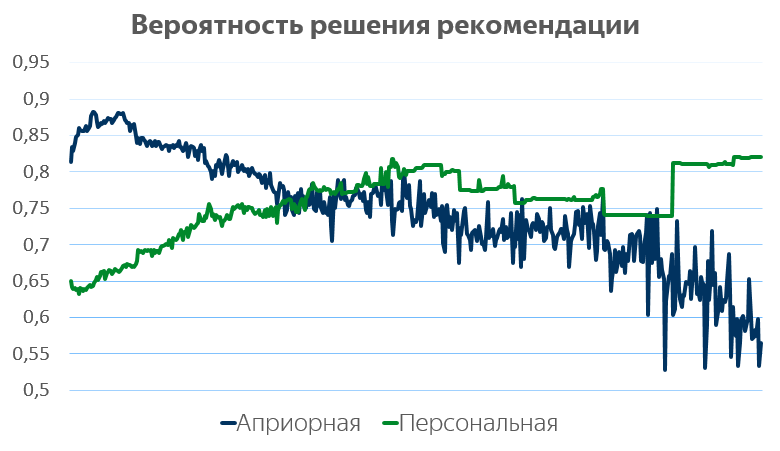
Хорошо видно, что поначалу мы предлагаем достаточно простые задачи, которые решаются с вероятностью 80-90%. Затем сложность постепенно нарастает, так что после нескольких сотен решённых задач их априорная вероятность решения снижается до 50%. Одновременно вероятность, что пользователь решит рекомендованную ему задачу, вырастает с 65% почти до 80%. Таким образом, пользователи наших «умных» рекомендаций всё лучше решают всё более сложные задачи!
Здесь я обязан сделать методологическое замечание: сказанное не доказывает, что наши рекомандации являются причиной роста успешности пользователей. Для такого вывода нужно провести корректное A/Б-тестирование. Например, возможен такой случай: более успешные школьники решают большее количество рекомендованных задач и график показывает только это, хотя при построении персональной модели сложности применялись различные методы для минимизации этого смещения. Тем не менее, приведённый график оставляет возможность того, что причиной являются именно рекомендации.
Есть, впрочем, один факт, который можно установить со всей определённостью. Оказывается, управляя только набором рекомендуемых задач (не меняя расположение блока рекомендаций, его визуальное представление или набор пользователей), можно статистически значимо влиять на количество решаемых задач.
Эти графики устроены так: по горизонтали — число решённых рекомендованных задач, по вертикали — число пользователей, решивших не менее выбранного числа рекомендованных задач.
Хорошо видно, что «умные» рекомендации намного сильнее вовлекают пользователей. Некоторые особенности графиков вызваны тем, что на сервисе рекомендации выдаются блоками — по несколько десятков задач в день.
Что дальше
В статье я попытался показать, какого рода данные можно собирать, анализировать и использовать во благо общества при помощи сервисов, подобных Яндекс. Репетитору.
Очевидно, это не исчерпывающий набор возможных применений. Самое простое, что приходит на ум: анализ ошибочных ответов в задачах, определение причин ошибок и дальнейшее использование полученного знания в образовательном процессе. Стоило бы также поискать зависимости между темами. Скажем, школьник, плохо справляющийся с дробями, вряд ли преуспеет в решении задач по теории вероятностей. Думаю, неравнодушные читатели смогут придумать множество приложений, которые я даже не упоминал в статье.
Мы продолжим работать в этом направлении, будем улучшать методику экспериментов и, я надеюсь, в конечном счёте преуспеем.
Извлечь смысл. Проблемы анализа данных в образовании
DOI 10.22394/2078−838Х−2021−3−60−64
В октябре 2021 года состоялась II Международная научно-практическая конференция «Большие данные в образовании: доказательное развитие образования». На мероприятии прошел круглый стол по проблематике архитектуры данных и аналитики данных в образовании. Предлагаем вашему вниманию фрагменты докладов некоторых участников.
Большие данные в образовании, архитектура данных, интерпретация данных.
Конференция прошла при поддержке Российского фонда фундаментальных исследований (проект № 19−29−14 016, руководитель О. А. Фиофанова).
Алексей Семенов. За последние годы московское образование сделало огромный шаг вперед в сторону цифровизации. В частности, «Московская электронная школа» стала общим цифровым пространством для всех московских учителей, учащихся и родителей нашего города.
В течение десятилетий Российский фонд фундаментальных исследований был источником грантового финансирования для ученых, занимающихся исследованиями в области точных, естественных и гуманитарных наук. То, что мы в конце 2019 года, непосредственно перед тем, как разразилась пандемия, запустили программу фундаментальных исследований цифровой трансформации российской школы, оказалось предвидением. Сейчас мы находимся в середине этого большого проекта, в котором участвует более 60 коллективов из многих регионов России.
Собирая данные о каждой образовательной организации, о каждом учителе и учащемся, мы получаем объективную возможность доказательно оценивать работу человека в сравнении с ним самим, работу школы в сравнению с ней самой.
Как из больших данных извлечь показатели качества? Это очень важная задача. На самом деле, я думаю, что мы приближаемся к ее решению. Если мы сумеем это сделать, то, например, может оказаться, что лучшая школа Москва — та, в которой постепенно двоечников сменили четверочники.
Хотелось бы также подчеркнуть, что мы получаем большую помощь, в частности, от Департамента образования и науки города Москвы и от учителей в создании учебника «Цифровой мир». Большое спасибо.
Ольга Фиофанова. Рассуждая об извлечении смысла из аналитики данных, мы должны понимать, что смысл зависит от двух факторов: технологического (инфраструктура, архитектура данных в цифровых средах, стандарты анализа данных) и антропологического (обращение человека к данным для обоснования решений, знание методов анализа данных, понимание практического применения data-анализа).
Извлечение смысла из анализа данных — это человеческий фактор. Привычка обращаться к данным преобразуется в соответствующий способ мышления, основанный на построении информационных моделей, выявлении связи и структуры данных и оперировании ими.
А для педагога это еще и сверхчеловеческая задача: создать нма основе аналитики данных новые знаниевые системы — образовательные программы для развития мышления, data-грамотности, data-компетенций.
Таким образом, цикл управления данными связывается с циклом управления знаниями.
Данные — это еще не все. Важно извлекать из них смысл
И в этом — организационном — смысле — было бы правильным, полагаю, строить корпоративные системы обучения с использованием аналитики данных региональных систем образования. Такое организационное решение уже осуществлено, например, в Москве и Подмосковье: созданы, например, Корпоративный университет Правительства Московской области и Корпоративный университет Московского образования, ставший одним из победителей Всероссийского конкурса кейсов по анализу данных и доказательному развитию образования.
Это история о том, как аналитика данных в форме датасетов интегрируется в корпоративную систему обучения и развития компетенций педагогов и руководителей образования.
Обсуждая проблематику анализа данных и смыслообразования на основании такой аналитики, нужно понимать различие в уровнях управления и оперирования данными для развития образования.
Разные уровни управления — разные задачи анализа данных — разные смыслы для доказательного развития национальных, региональных систем образования, образовательных институтов и человеческого потенциала.
На уровне государственного управления объектом анализа являются данные по индикаторам национальных проектов и государственных программ развития образования, показатели мониторингов системы образования, данные Национальной системы оценки качества, международных исследований качества образования.
Технологическая инфраструктура данных этого уровня анализа:
а) Национальная система управления данными — ЕИП НСУД / наборы данных б) Портал госпрограмм — сводная аналитика в) OECD / Open Data и другие.
Основной проблемой этого уровня управления на основании данных остаются вопросы и вытекающие из них смыслы:
● как институциализируется «человеческое измерение» (гуманитарная аналитика) в системе управления на основании данных?
● как изменяются методики и индикаторы мониторингов образования, чтобы наиболее корректно отражать задачу «равные возможности для каждого»?
● как встраиваются инструменты Data-Anthropo в цифровые сервисы аналитики данных на отраслевом/межотраслевом, территориальном (региональном), государственном уровне?
На уровне организационного управления объектом анализа являются данные, отражающие развитие и управление образовательной организацией или управление образовательной платформой (например, РЭШ, МЭШ, ГИС СЦОС)
Технологическая инфраструктура данных этого уровня анализа: данные программ развития образовательных организаций, данные мониторинга системы образования данные по организациям, данные о развитии образовательной организации, ее кадровом потенциале, достижениях ее обучающихся, например в ЛК руководителя по мониторингу «Надежная школа».
Основной проблемой этого уровня управления остаются вопросы и вытекающие из них смыслы об институциональных (или платформенных) условиях развития человеческого потенциала, об институциональных данных качества образования, о связи аналитики данных с качеством преподавания и учения.
На уровне педагогической аналитики данных и педагогической организации индивидуальных образовательных траекторий, индивидуальных учебных планов объектом анализа являются данные, отражающие развитие человека, данные выборов, осуществляемых человеком среди образовательных программ, способов решения учебных и проектных задач, учебных затруднений человека, его мотивов и предпрофессиональных, жизненных устремлений.
Технологическая инфраструктура данных этого уровня анализа: архитектура данных в LMS университета / школы / образовательной организации.
Основной проблемой этого уровня управления остаются вопросы и вытекающие из них смыслы о стандарте цифровой образовательной среды и связанных с этим вопросом неравных возможностей обучения в средах технологически развитых с возможностью построения индивидуальных образовательных траекторий, рефлексией школьником / студентом собственных данных; по сравнению с цифровыми образовательными средами технологически неразвитыми, где таких возможностей нет). А также принципы аналитики данных в условиях смены модели образования и переходу к модели «Образование 4:0» («Дидактика 4:0»).
Для этого важно различать:
● Образование индустриальной эры — это предметно организованный учебный материал, контроль и анализ данных по освоенному объему знаний и репродуктивным навыкам — с соответствующей аналитикой данных.
● Образование постиндустриальной эры— это конвергентно организованный образовательный контент (содержание образования), деятельностная оценка и анализ данных по развитию продуктивной деятельности, анализ данных личных выборов в решении проектных задач. Так как кроме традиционных культурных норм важно развивать у поколения next собственную культурную норму управления собственным образованием, развитием на протяжении всей жизни.
Глубоко понимая смыслы вышеназванного, мы организовали разнообразные формы поддержки культуры data-анализа:
1) Международная конференция «Анализ данных в образовании: доказательное развитие образования»;
2) Всероссийский конкурс кейсов по анализу данных и доказательному развитию образования;
3) Образовательную программу высшего образования «Управление образованием на основании данных. Проект получил финансовую поддержку Фонда Владимира Потанина и стал победителем конкурса на предоставление грантов преподавателям магистратуры 2020/2021 благотворительной программы «Стипендиальная программа Владимира Потанина» благотворительного фонда Владимира Потанина.
В настоящее время эта новая программа магистратуры готовится к аккредитации. Мы будем рады увидеть в числе магистрантов этой программы читателей журнала «Образовательная политика».
Организационные формы поддержки мы развивали также на основе анализа данных, но в данном случае — Data-Science — научных данных.
Результаты проекта 19-29-14016 фундаментального научного исследования «Методология анализа данных и ее интеграция в программы профессиональной подготовки педагогов и руководителей образования», поддержанного грантом Российского фонда фундаментальных исследований.
Ольга Бабченко. Екатеринбург — один из крупнейших городов России. Система образования мегаполиса в процессе работы обрастает огромным количеством данных и мониторинговых систем. Но, как известно, данные — это еще не все. Важно извлекать из них какой-то смысл. Вопрос об оптимизации работы со значительным объемом накопленных данных — один из самых актуальных в управленческой деятельности на муниципальном уровне.
Большие данные позволяют решать важные задачи, например, оценивать особенности функционирования образовательного комплекса, оперативно реагировать на изменения и отклонения в результатах и определять перспективы развития, повышать управляемость системы. Одной из значимых характеристик системы на современном этапе является то, что образование уже давно вышло за рамки образовательной организации. Это происходит через интеграцию систем общего и дополнительного образования, через введение в эксплуатацию различных инновационных структур, таких как «Кванториумы», IT-кубы, через реализацию сетевых образовательных программ. В Екатеринбурге эти процессы развиваются очень активно.
Все наши потоки данных так или иначе ориентируются на нашу внутреннюю систему. Выходить за рамки образовательной организации нам пока очень сложно. Мы еще не отработали конкретные механизмы.
В системе образования Екатеринбурга работает несколько автоматизированных информационных систем, самой крупной из них является так называемая АИС «Образование», которая эксплуатируется и развивается более 15 лет. Мы думаем, что мы уже создали мощного «монстра», который содержит огромное количество модулей. Из этой системы мы можем взять статистические данные, которые касаются сети образовательного комплекса и контингента, которые говорят о результатах муниципальной оценки системы качества образования, о результатах участия школьников во всероссийских олимпиадах, о динамике и результатах физической подготовки обучающихся. В общем, по разным направлениям.
Объем данных огромен, но он нас не удовлетворяет, поскольку во внешнее пространство системы мы выходим по минимальным показателям.
Какие риски и системные проблемы муниципального уровня для обработки больших данных мы видим? Проблемой является недостаток финансовых ресурсов для модернизации существующих систем и их интеграции с федеральными и региональными платформами и автоматизированными системами для обеспечения больших объемов дискового хранилища. Отсутствует достаточное количество квалифицированных специалистов и экспертов для анализа статистических данных и получения выводов. Сложность интерпретации данных на муниципальном уровне возникает из-за многообразия особенностей функционирования учреждений.
Мы очень надеемся на интеграцию внутренних и внешних потоков данных. Например, актуальной для нас является задача интеграции муниципальной и федеральной систем оценки качества.
Необходимо использовать автоматизированные информационные системы, чтобы оперативно решать вопросы, возникающие у населения. Сейчас мы начали отрабатывать такой опыт. Например, при изменении законодательства в части регулирования перевода детей из одного дошкольного учреждения в другое заявитель должен в обязательном порядке согласовывать все эти моменты с учредителем.
Илья Бронштейн. Существующие системы, будь то электронный дневник или система записи в школу, часто напоминают монстров, потому что обрастают гигантскими модулями, каждый из которых генерирует какое-то количество информации. Это приводит к перегрузке информационной системы, потому что по прошествии нескольких лет никто уже не помнит, какие смыслы закладывались в тот или иной модуль.
Мы научились собирать и генерировать данные, мы научились видеть между ними связи. Но какие выводы мы можем делать на основе этих данных? Весной прошлого года мы, как и вся страна, были вынуждены перейти на дистанционное обучение. Мы поняли, что цифровая интерпретация результатов выполненных учениками тестов часто отличается от той интерпретации, которую учитель дает в классе. Можем ли мы сказать, что автоматическая оценка более достоверна, чем та, которую поставил учитель? Уверен, что нет. Уверен, что мнение учителя должно главенствовать.
Но как тогда сопоставить мнение учителя с результатами, которые получил ребенок? Я не знаю действенных инструментов, позволяющих в системе образования анализировать большие данные и делать достаточно достоверные выводы. Хочу подчеркнуть, что для Московской области такие решения были бы очень важны. У нас сегодня почти миллион школьников, у нас сложная социальная и территориальная структура. У нас, например, есть школы, расположенные в труднодоступных населенных пунктах, есть большие городские школы, сельские школы и т. д.
И понятно, что структура данных, необходимых для принятия тех или иных управленческих решений, тоже будет разной. И поэтому для нас очень важно найти такие инструменты. Мы в поиске. Московская область готова обсуждать решения, готова к сотрудничеству.
Нияз Габдрахманов. Мы прекрасно знаем практики работы с большими данными университетов и образовательных учреждений другого уровня. Эти организации генерируют колоссальное количество данных. С точки зрения ресурсной составляющей мы эту проблему фактически решили. Проблема заключается в другом. К сожалению, эти данные никак не используются, на их основе не принимаются управленческие решения.
Несколько лет подряд мы проводим исследования, посвященные анализу социального самочувствия студентов, и оперируем данными социальной сети «ВКонтакте».
Мы собираем цифровые следы в рамках консорциума. Вузы становятся инициаторами работы с большими данными. На мой взгляд, это важный сдвиг.
Вместе с тем есть очень важные ограничения с точки зрения использования этих данных. Все-таки данные, которые генерируются образовательными учреждениями, носят некий индивидуальный характер. Нужно искать механизм, который позволит их деперсонализировать.
Вторая проблема: как сшивать разные форматы таблиц и данных? Ведь зачастую в образовательных учреждениях данные генерируются очень разнородные по структуре.
Еще одна проблема заключается в том, что данные, которые генерируются внутри образовательного учреждения, как правило, находятся в разных структурных подразделениях. Данные по школам хранятся в Министерстве просвещения, данные по вузам — в Министерстве науки и высшего образования. Межведомственное взаимодействие по обмену данными налажено пока слабо. При этом, когда мы говорим об образовательной успешности, важно наблюдать поступление человека в школу, его обучение в школе, в вузе.
Поэтому я хотел бы акцентировать внимание на этих трех основных компонентах: работа с персональными данными, структура данных и, конечно же, межведомственные взаимодействия как внутри образовательных учреждений, так и между министерствами ведомств.
Extract meaning. Problems of data analysis in education
In October 2021, the II International Scientific and Practical Conference «Big Data in Education: Evidence-based development of education» was held. A round table on the problems of data architecture and data analytics in education was held at the event. We bring to your attention fragments of reports of some participants.
Big data in education, data architecture, data interpretation.
Если статья была для вас полезной, расскажите о ней друзьям. Спасибо!
Программы
ШАД Яндекс предоставляет 5 программ на выбор.
Школа анализа данных от VK предоставляет 3 программы на выбор.
AI Masters предлагают 2 направления.
Разделение на специальности является условным, так как курсы для всех похожи. Кроме того, можно выбирать любые курсы из других специальностей. Поэтому лучше выбирать не по названию специальности, а по перечню обязательных курсов, входящих в ее программу.
Как проходит учеба в школах?
Обучение по всем программам проходит на бесплатной основе.
ШАД Яндекс — занятия по вечерам 3 раза в неделю, много домашних заданий, 3 курса за семестр, всего обучение длится 4 семестра. Учиться надо много по 30–40 часов в неделю. Можно полностью удаленно учиться и общаться со студентами и преподавателями из ШАД.
В Школе анализа данных от VK обучение длится 2 семестра. Учиться надо по 25–40 часов в неделю. Можно очно учиться в МИСИС или удаленно. Нет платного отделения.
В AI Masters обучение длится 2 года по вечерам, занятость примерно 30 часов в неделю.
Выводы
Таким образом, ШАД Яндекс предназначен для будущих экспертов, Школа анализа данных от VK — для людей с опытом, а AI Masters — для тех, кто стремится стать бизнес‑аналитиком или математическим гуру.
Для поступления в эти школы необходимо иметь твердые знания в математике, опыт участия в олимпиадах по программированию или индустриальный опыт в области Data Science. Однако, главное — это готовность учиться много и постоянно, независимо от выбранного пути.



