

Для создания междоменных отношений доверия используется оснастка «Active Directory — домены и доверие».
Минимальное требование для выполнения этой процедуры — членство в группе Администраторы домена или Администраторы предприятия или в эквивалентной группе. Подробные сведения об использовании соответствующих учетных записей и членства в группах см. на странице https://go.microsoft.com/fwlink/?LinkId=83477.
С помощью оснастки «Active Directory — домены и доверие» можно задать область проверки подлинности для пользователей, проверка подлинности которых выполняется через внешние доверия или доверия лесов.

Методы Градиента политики (PG) популярны в обучении с подкреплением (RL). Основной принцип использует градиентный подъем, чтобы следовать политике с самым резким увеличением вознаграждения. Однако оптимизатор первого порядка не очень точен для криволинейных участков. Мы можем проявлять излишнюю самоуверенность и делать неверные шаги, которые портят ход обучения. TRPO — одна из наиболее цитируемых статей по этому вопросу. Тем не менее, TRPO часто объясняется без надлежащего введения основных понятий. В части 1 мы сосредоточимся на проблемах PG и представим три основных концепции: алгоритм MM, область доверия и выборка важности. Но если вы уже знакомы с этими концепциями, прокрутите до конца часть 2, в которой подробно рассматривается TRPO.
Проблемы методов градиента политики (PG)
В RL мы оптимизируем политику θ для получения максимально ожидаемых скидок. Тем не менее, есть несколько проблем, которые ухудшают производительность PG.

Сначала PG вычисляет направление наискорейшего подъема для вознаграждений (градиент политики g) и обновляет политику в этом направлении.

Однако этот метод использует производную первого порядка и приближает поверхность к плоской. Если поверхность имеет большую кривизну, мы можем делать ужасные движения.

Слишком большой шаг ведет к катастрофе. Но если шаг слишком мал, модель учится слишком медленно. Представьте функцию вознаграждения в виде горы наверху. Если новая политика зайдет слишком далеко, она предпримет действия, которые могут оказаться на дюйм слишком далеко и упасть со скалы. Когда мы возобновляем исследование, мы начинаем с плохо работающего состояния с плохой локально политикой. Производительность падает, и восстановление займет много времени, если вообще когда-либо.

Во-вторых, очень трудно иметь надлежащую скорость обучения RL. Предположим, скорость обучения специально настроена для желтого пятна выше. Эта область относительно плоская, поэтому скорость обучения должна быть выше средней для хорошей скорости обучения. Но один неудачный ход, мы падаем со скалы на красную точку. Градиент у красной точки высокий, и текущая скорость обучения вызовет взрывное обновление политики. Поскольку скорость обучения не зависит от местности, PG сильно страдает от проблемы сходимости.
В-третьих, следует ли ограничивать изменения в политике, чтобы не предпринимать слишком агрессивных шагов? Фактически, это то, что делает TRPO. Он ограничивает изменения параметров, чувствительные к местности. Но предоставление этого решения неочевидно. Мы корректируем политику по параметрам модели низкого уровня. Каковы соответствующие пороговые значения для параметров модели, чтобы ограничить изменение политики? Как мы можем преобразовать изменение пространства политики в пространство параметров модели?
В-четвертых, мы отбираем всю траекторию только для одного обновления политики. Мы не можем обновлять политику на каждом временном шаге.

Почему? Визуализируйте модель политики как сеть. Увеличение вероятности π (s) в одной точке также подтянет вверх соседние точки. Состояния внутри траектории похожи, особенно когда они представлены необработанными пикселями. Если мы обновляем политику на каждом временном шаге, мы эффективно подтягиваем сеть несколько раз в одинаковых точках. Изменения усиливают и усиливают друг друга и делают тренировку очень чувствительной и нестабильной.

Учтите, что траектория может состоять из сотен или тысяч шагов, одно обновление для каждой траектории не является эффективным для выборки. PG требуется более 10 миллионов шагов по времени для игрушечных экспериментов. Для реального моделирования в робототехнике это слишком дорого.
Итак, давайте резюмируем технические проблемы PG:
Оглядываясь назад, мы хотим ограничить изменения в политике, и, что еще лучше, любое изменение должно гарантировать улучшение вознаграждений. Нам нужен лучший и более точный метод оптимизации, чтобы создавать более совершенные политики.
Чтобы понять TRPO, лучше сначала обсудить три ключевые концепции.
Алгоритм Minorize-Maximization MM
Можем ли мы гарантировать, что любые обновления политики всегда улучшают ожидаемые награды? Кажется привлекательным, но теоретически это возможно. Алгоритм MM достигает этого итеративно, максимизируя функцию нижней границы (синяя линия ниже), аппроксимируя ожидаемое вознаграждение локально .

Давайте рассмотрим подробнее. Начнем с первоначального предположения о политике. Мы находим нижнюю границу M, которая приблизительно соответствует ожидаемому вознаграждению η локально при текущем предположении. Мы находим оптимальную точку для M и используем ее в качестве следующего предположения. Снова аппроксимируем нижнюю границу и повторяем итерацию. В конце концов, наше предположение сведется к оптимальной политике. Чтобы это работало, M должно быть проще оптимизировать, чем η. Предварительный просмотр , M — квадратное уравнение.

но в векторном виде:

Это выпуклая функция, и способы ее оптимизации хорошо изучены.
Почему алгоритм MM сходится к оптимальной политике? Если M является нижней границей, он никогда не пересечет красную линию η. Но позвольте предположить, что ожидаемое вознаграждение за новую политику ниже в η. Тогда синяя линия должна пересекать η (рисунок справа внизу) и противоречить тому, что это нижняя граница.

Поскольку у нас есть ограниченные политики, поскольку мы сохраняем итерацию, это приведет нас к локальной или глобальной оптимальной политике.
Теперь мы находим ту магию, которую хотим.
Оптимизируя функцию нижней границы, приближающую η локально, он гарантирует улучшение политики каждый раз и в конечном итоге приводит нас к оптимальной политике.
Доверительный регион
Существует два основных метода оптимизации: линейный поиск и область доверия. Градиентный спуск — это линейный поиск. Сначала мы определяем нисходящее направление, а затем делаем шаг в этом направлении.

В доверительной области мы определяем максимальный размер шага, который хотим исследовать, а затем находим оптимальную точку в этой доверительной области. Начнем с начального максимального размера шага δ как радиуса доверенной области (желтый кружок).
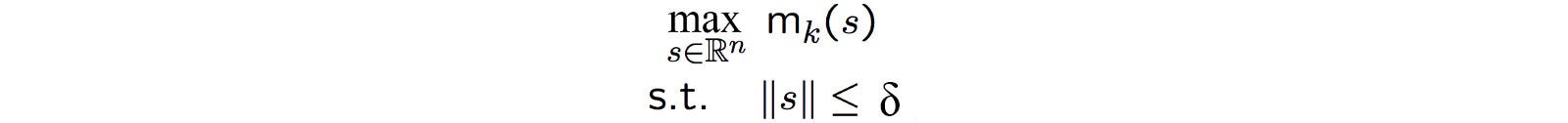
m — это наше приближение к исходной целевой функции f. Теперь наша цель — найти оптимальную точку для м в радиусе δ. Мы повторяем процесс итеративно до достижения пика.

Чтобы лучше контролировать скорость обучения, мы можем расширять или сокращать δ во время выполнения в соответствии с кривизной поверхности. В традиционном методе доверительной области, поскольку мы аппроксимируем целевую функцию f с помощью m, одна из возможностей состоит в том, чтобы уменьшить доверительную область, если m является плохой аппроксиматор f в оптимальной точке. Напротив, если приближение хорошее, мы расширяем его. Но вычислить f в RL может быть непросто. В качестве альтернативы, мы можем уменьшить регион, если расхождение новой и текущей политики становится большим (или наоборот). Например, чтобы не впадать в излишнюю самоуверенность, мы можем уменьшить зону доверия, если политика слишком сильно меняется.
Выборка по важности
Выборка по важности вычисляет ожидаемое значение f (x), где x имеет распределение данных p.

При выборке по важности мы предлагаем выбор не производить выборку значения f (x) из p. Вместо этого мы отбираем данные из q и используем отношение вероятностей между p и q для повторной калибровки результата.
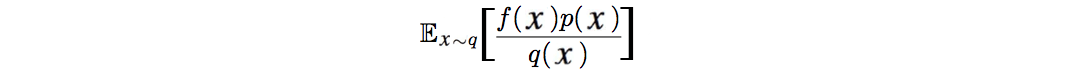
В PG мы используем текущую политику для вычисления градиента политики.

Поэтому всякий раз, когда политика меняется, мы собираем новые образцы. Старые образцы не подлежат повторному использованию. Таким образом, PG имеет низкую эффективность выборки. С помощью выборки по важности нашу цель можно переписать, и мы можем использовать образцы из старой политики для расчета градиента политики.
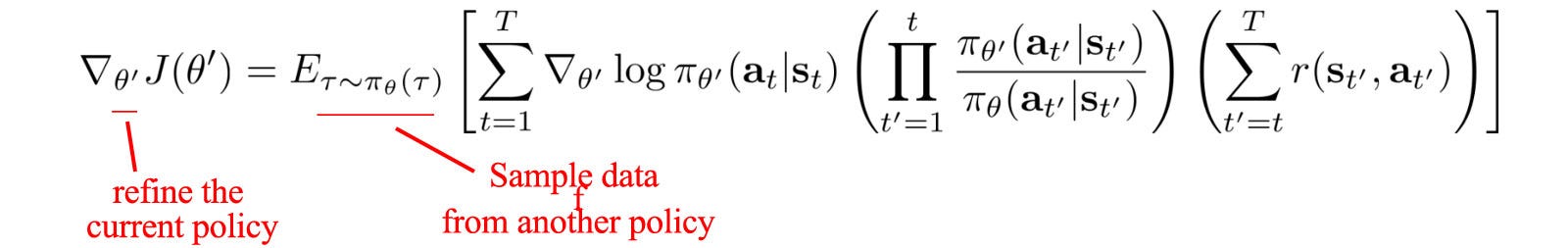
Но есть одно предостережение: оценка с использованием q,

Если отношение P (x) / Q (x) высокое, дисперсия оценки может резко возрасти. Таким образом, если две политики сильно отличаются друг от друга, разница (также известная как ошибка) может быть очень высокой. Поэтому мы не можем использовать старые образцы слишком долго. Нам все еще нужно довольно часто пересчитывать траекторию, используя текущую политику (скажем, каждые 4 итерации).
Целевая функция с использованием выборки по важности
Давайте подробно рассмотрим применение концепции выборки по важности в PG. Уравнения в методах PG градиента политики:
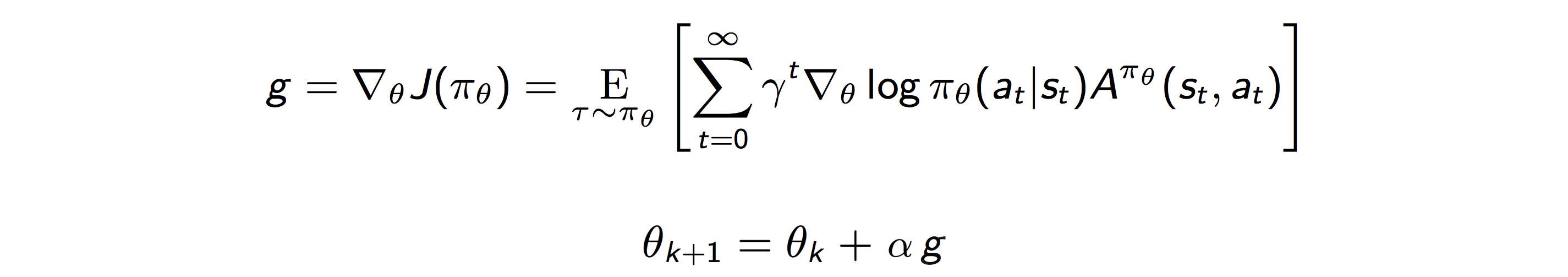
Мы можем обратить эту производную и определить целевую функцию как (для простоты иллюстрации γ часто устанавливается равным 1):
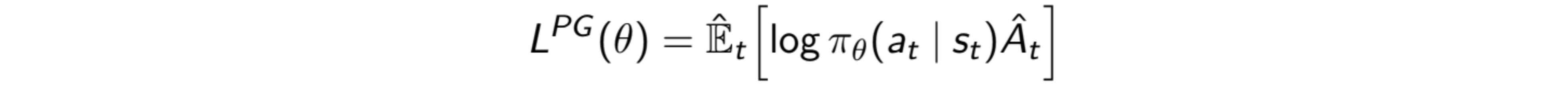
Это также может быть выражено как выборка по важности (IS):

Как показано ниже, производные для обеих целевых функций одинаковы. т.е. у них одинаковое оптимальное решение.
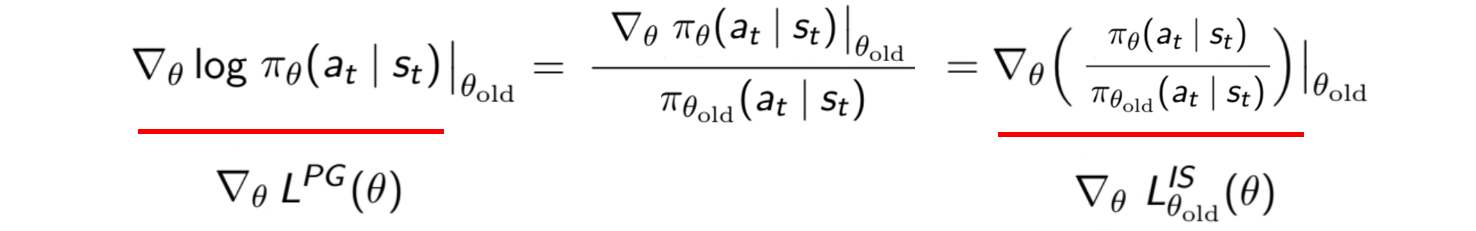
Наличие двух политик в цели оптимизации дает нам формальный способ ограничить изменение политики. Это ключевая основа многих передовых методов градиента политики. Кроме того, это может дать нам возможность оценить возможные политики, прежде чем мы зафиксируем изменение.
Теперь мы закончили три основных концепции, которые нам нужны для нашего обсуждения, и готовы к последней части TRPO.
Для тех, кому интересно ознакомиться со статьями этой серии по глубокому обучению с подкреплением.
Создание междоменного доверия
Совсем недавно вернулся с очередной рабочей встречи с уважаемым Заказчиком, на которой мы долго и чрезвычайно увлекательно дискутировали о необходимых затратах и, соответственно, стоимости небольшого подпроекта. На встрече было человек шесть с достаточно высокими грейдами, развитыми навыками коммуникации, ведения переговоров и большим опытом аргументации своей позиции. Встреча затянулась, стороны были настойчивы и в результате сошлись на компромиссном результате – Заказчик получил скидку, сравнимую со стоимостью потраченного времени на ее выбивание. То есть в финансовом выражении результат встречи близок к нулю, потраченное время уже никогда не восполнить, но при этом удалось приблизиться к завершению и передаче Заказчику требуемой ценности. И всю дорогу обратно я задавался вопросом – а можно было бы решить задачу более эффективно? Можно ли было сохранить время и ресурсы, свои и заказчика, но при этом добиться того же результата? Где та точка роста, которая позволит решать задачи быстрее, а тратить меньше?
И здесь я бы хотел поговорить про доверие между Исполнителем и Заказчиком. Существует общераспространённое мнение, что в условиях высокого доверия между сторонами проектной команде работается проще, проекты успешнее, результат для Заказчика значительнее, а выручка (прибыль, etc) Исполнителя выше.
Осознано размышлять на тему я начал после знакомства со статьей уважаемого А. Орлова в мою бытность студентом Стратоплана. Если кратко, то в статье приведено описание эволюции доверия с ростом прозрачности. Основная задача была выстроить долговременные отношения с Заказчиком и обеспечить небольшой, но постоянный поток работы. В отличие от проектов с конкретными сроками и результатами, после которых команда распускалась и следующий проект мог быть организован спустя продолжительное время, с одним из Заказчиков была выстроена схема с постоянными заказами на развитие функционала. При этом согласование каждого заказа занимало до 1 месяца, во время которого функциональность не создавалась, команда стояла, бизнес-заказчик грустил в ожидании. По итогу согласования проект запускался, команда начинала свою работу и, как часто бывает, заказчик начинал вносить изменения, что влекло за собой пересмотр условий, затягивание времени и все вытекающие сложные ситуации. В общем, идеальный кандидат для эксперимента в области доверия. Цель же эксперимента была определена как сократить издержки при сохранении уровня выручки.
Как и было рекомендовано в статье, начал с повышения уровня прозрачности. Для этого все предлагаемые сметы на услуги были максимально детализированы в части набора задач, ставки открыты, результаты и ограничения строго формализованы. Вторым действием стало предложение заключать контракты уже после выполнения работы с учетом реальных затрат по табелям учета рабочего времени плюс анализ внедренных изменений, которые появились в ходе выполнения задачи. Заказчик при этом ничем не рисковал, так как договорились, что стоимость не будет выше, чем озвученная. За счет этого упражнения мы продемонстрировали адекватность оценок и влияние нечеткой постановки на финальные результаты. Второй плюс – заказчик очень тесно знакомился с командой и спецификой работы. Уже на этом этапе я, как руководитель проекта, получил выгоду в сокращении затрат на согласование, поскольку у Заказчика больше не было причин детально разбирать смету, но появился реальная заинтересованность как можно более четко формализовать задачу и здесь коллеги из ИТ самостоятельно работали с бизнес-заказчиком над уточнением требований. И в такой схеме мы жили примерно 9 месяцев, по прошествию которых выяснилось, что затраты Заказчика остались на прежнем уровне, команда потратила на 20% больше времени, при этом скорость выводы функционала и удовлетворенность заказчика субъективно выросли за счет отказа от многочисленных обсуждений CR’ов и кто в них виноват. Рост затрат был обусловлен ранним стартом и отличиями в постановке от финальной реализации.
Обсудив текущее положение с Заказчиком (открытость — помните?), пришли к гипотезе, что если:
то можно получить больше функционала за меньшие деньги, сохранив интерес и доверие Исполнителя, что дает возможность оперативно наращивать объем без долгих контрактных процедур. При этом соглашусь – часть рисков Заказчик взял на себя, но получил больше гибкости при реализации.
На текущий момент согласования смет забыты, заключен один контракт на год с легкой процедурой продления, стабильная и полностью устраивающая Заказчика команда постоянно выдает результат в эксплуатацию, создавая сложные и плохо формализуемые в начале работ компоненты. Я, как Исполнитель, получил постоянный доход на конкурентном рынке с минимальным уровнем риска и легкопрогнозируемой доходностью. При этом 95% усилий идет на создание ценности вместо танцев вокруг сметы.
Буду пробовать повышать уровень доверия с другими Заказчиками, посмотрим, куда это приведет.



